My portfolio
I'm a passionate Data Scientist but more important I'm passionate about technology.
I'm a passionate Data Scientist but more important I'm passionate about technology.

This project investigates optimal dynamic pricing strategies for an online retailer to maximize revenue in the face of uncertain demand. It employs advanced models to analyze price sensitivity and predict demand, formulating a revenue maximization problem within a finite period. The study emphasizes the impact of pricing on inventory management and consumer behavior.

I developed a web-based loan default prediction system leveraging FastAPI and machine learning. The system efficiently predicts loan defaults using a FastAPI backend for API management, integrated with a Pydantic-based data model for structured, type-safe input. The frontend, crafted with HTML, JavaScript, and styled with CSS, offers an intuitive user interface. The application is containerized using Docker for consistent deployment across environments. Additionally, GitHub Actions automate testing and linting, ensuring code quality and functionality in this full-stack AI solution for the financial sector
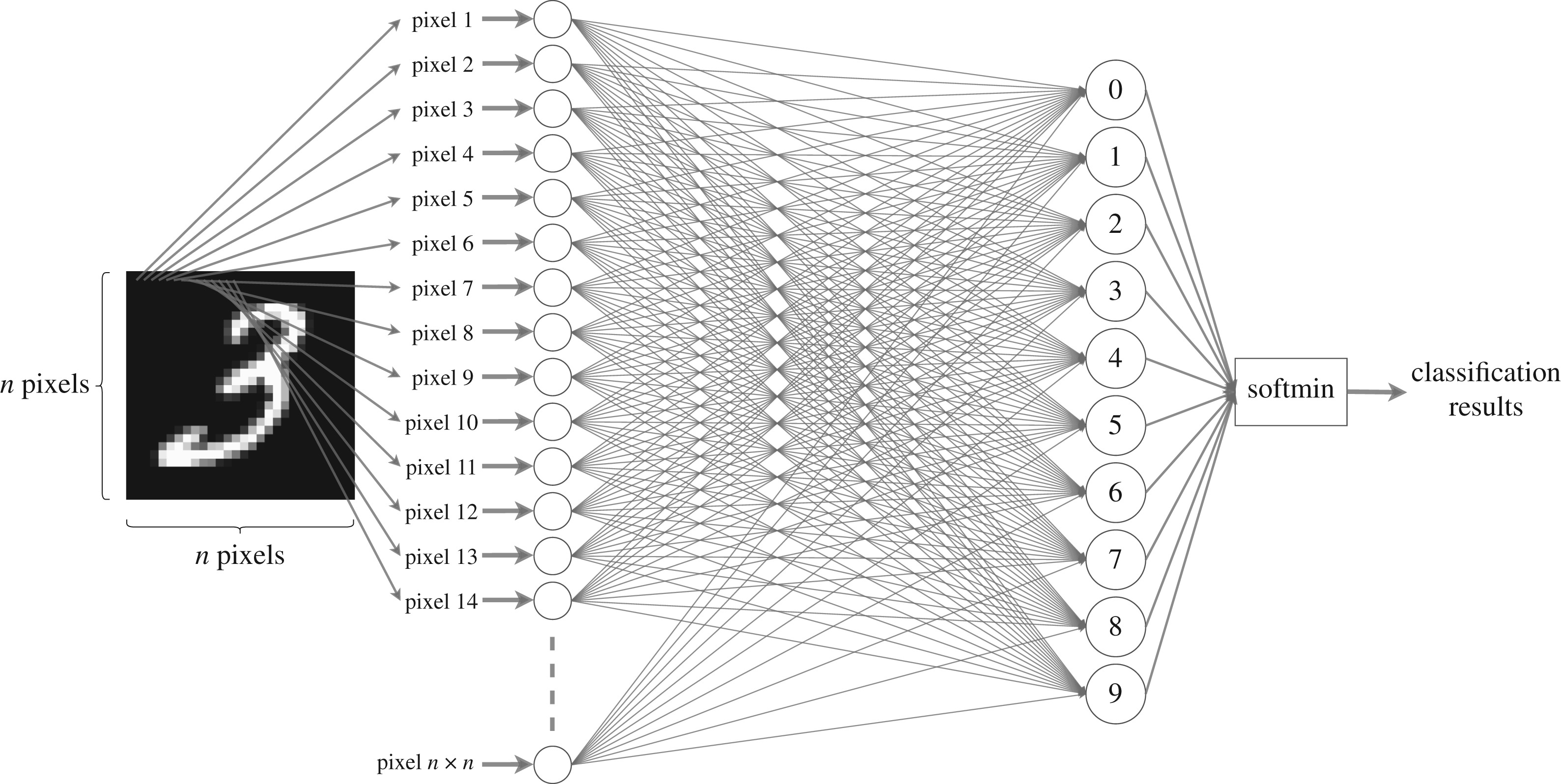
This project explores the frontiers of image classification by utilizing the CIFAR-1000 dataset, a rich and diverse collection of images. We designed unique neural network architectures alongside leveraging a pretrained model, aiming to compare and understand their respective efficacies. Critical to our approach was the incorporation of dropout and data augmentation techniques. Dropout served as a regularization method to reduce overfitting, while data augmentation expanded our dataset's variability, leading to a more robust model. The combination of these strategies aimed to improve the model's generalization on unseen data, representing a comprehensive effort in advancing image classification capabilities.

This project aims to manage financial risk by predicting loan defaults among clients. It utilizes supervised learning techniques, specifically Decision Tree (DT) and Random Forest (RF), for this classification task. The project's heart lies in a detailed comparison and evaluation of both models, leveraging various metrics to determine their effectiveness.

This study focuses on analyzing customer transactions from 2011, sourced from the UCI Machine Learning repository. The primary goal is to enhance demand forecasting in the retail sector. Key aspects of the analysis include evaluating the impact of various variables on consumer demand and uncovering hidden patterns in customer behavior. By delving into buying patterns and demographics, the study aims to reveal insights that are crucial for understanding current market trends.

This project is a showcase where data engineering techniques are applied and predictions are made through different machine learning models. In addition to this, each model will be evaluated through different metrics and plots.

This project is Kaggle competition of Microsoft of 2016 where the goal was to make a model which predicts if a computurer was going to be infected. In other other hand, to achieve this prediction data understanding, preparation, modeling and evaluation are carried out
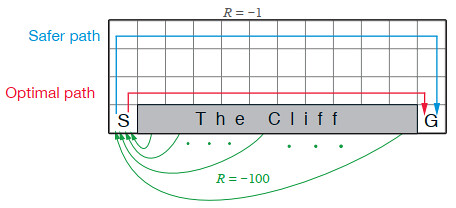
The Walking Cliff project is a reinforcement learning task where an agent, represented by a simple stick figure, must learn to navigate a cliff-like environment without falling. The agent receives rewards for reaching the end of the cliff and penalties for falling off. The project is designed to showcase the capabilities of reinforcement learning algorithms, which enable agents to learn from trial and error using a system of rewards and punishments.

In this project the goal is to predict student performance during game-based learning in real-time, using one of the largest open datasets of game logs available. It’s being developed a model that utilizes knowledge tracing to support individual students in educational games, with the hope of making game-based learning more effective and accessible to everyone. Through this project, I have the opportunity to contribute to advancing the field of educational technology and make a real difference in the lives of students.

Our data science project aims to improve sales forecasting and optimize marketing strategies for DSMarket. We will analyze sales data to understand product popularity variations across cities and stores. By developing advanced predictive models, we aim to accurately forecast sales at a store-product level, enabling better supply chain management. Additionally, we will conduct clustering analysis to identify groups of products with similar behavior and explore store clustering to understand operational characteristics. The outcome will be tailored marketing strategies that resonate with specific city and store preferences, leading to improved decision-making and reduced excess inventory.